


What is Gemini Ultra?
Well if you have not been living under a rock you will know that Google’s latest announcement is set to dethrone OpenAI’s Chat GPT. Here is what Gemini scored in the last exams it took:
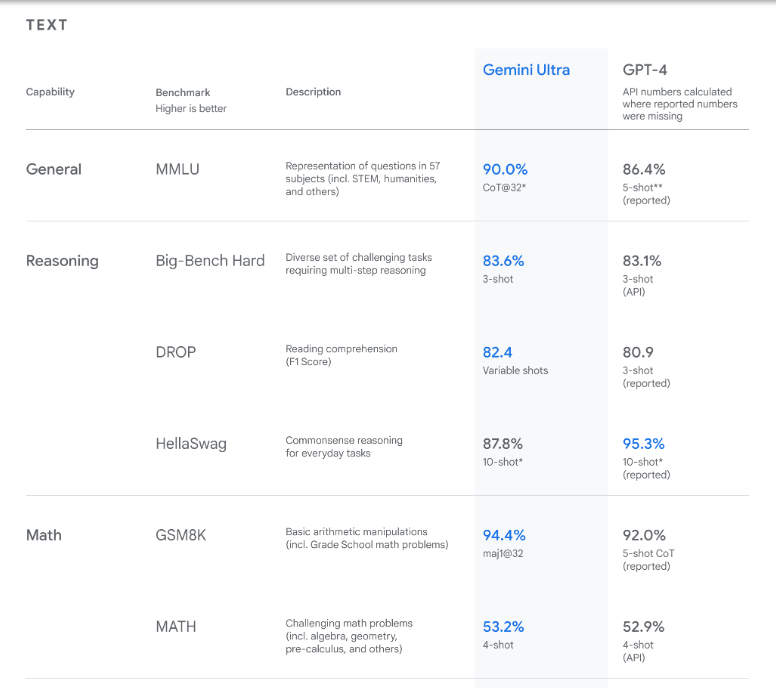
If you are a frequent reader of mine you will know what most of these exams mean, if not, here is where I explain it
Again this is a captured image from google https://blog.google/technology/ai/google-gemini-ai/#capabilities and even tho there are more things to analyze from Gemini Ultra because its a multimodal Large Language Model, just like Chat GPT, let’s just focus on the TEXT part of it
You immediately see that, according to Google, Gemini is better than GPT-4.
Is it though?
When we look really deep into the details, where the devil lies…
If we see the results for MMLU, we see Gemini scoring 90% compared to 86.4% which is better but the difference is not relevant. But let’s go deeper, the way they reached that scoring was thru “COT@32” and GPT-4 thru 5-shots.
What does that mean?
I have a full article about that here is you want to go where the devil is if not, keep reading:
It means that GPT-4 only needed 5 different prompts to get to 86.4% whereas Gemini needed Chain-Of-Thought prompting which in essence means to step-by-step feed the AI with relevant information about the task and only after feeding it 32 prompts, you can reach that 90%.
Ergo, if a prompt takes you 5 minutes (which is a lot of time but bear with me), you can get an 86.4% accuracy in 25 minutes. On the other hand, feeding 32 prompts and specially with CoT that takes more than your regular generic prompt but let’s just assume it takes you the same amount of time, it means you get to 90% after 2 hours and 45 minutes, give or take.
Since here at PotenzaGPT, we are so into Prompting Engineering, we know that prompting for almost 3 hours is not only exhausting, It is not productive, definitely not a great system and it will make users disregard the actual possible benefits of this new AI technology.
But let’s move on
Big-Bench Hard is fair game but the actual difference in test scores between them is 0,5%.
DROP we get an 82.4 compared to 80.9 but they claim it was “variable shots” compared to 3-shots. How many actual “variable shots” are there?
But I just love how they did the Math part of the tests:
MATH exam was 53.2% for Gemini and 52.9% for GPT-4 being fair game but we see GSM8K which is another math exam
The results are 94.4% for Gemini and 92% for GPT-4 with 5-shots CoT but Gemini used this unbelievable and just perfect “Maj1@32” technique that is so unique that the entire Internet and LLMs do not even know what that actually means.
We went through the entire report looking for it and we could not find it. We asked Bard and it claimed that maybe it’s an inside technique from Google that they do not mean to publish “just yet”.
The Underappreciated Art of Prompt Engineering
In the shadow of the titanic clash between AI giants lies a skill subtler yet equally powerful: prompt engineering. This craft, often underappreciated, is where the true potential of AI like Gemini Ultra a
nd GPT-4 is unlocked.
For this article we did quite the research but the main report is Microsoft’s claim that GPT-4 can outperform Gemini Ultra.
Here is Microsoft’s claim:
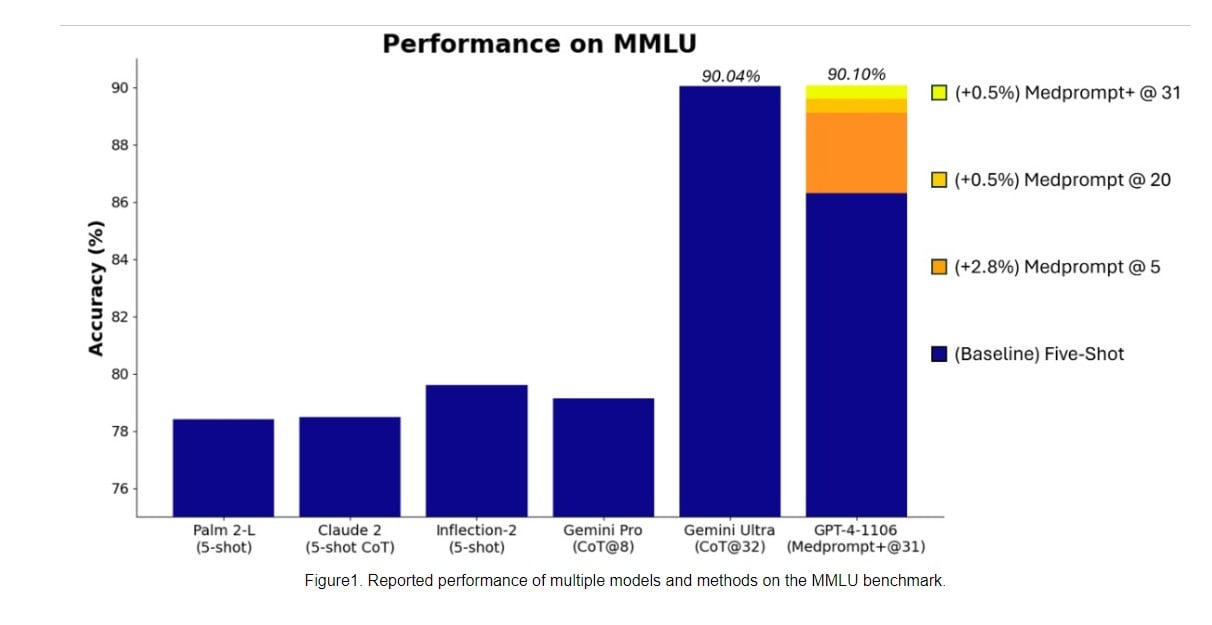
They claim that thru MedPrompt, a technique used in another academic report that we also read, GPT-4 can outperform Gemini Ultra reaching on MMLU test all the way to 90.10%
Gemini Ultra only reached 90.04%. Not a real staggering difference.
Here is the comparison with other benchmarks:
And also some really interesting graphics that the MedPrompt+ paper gave us:
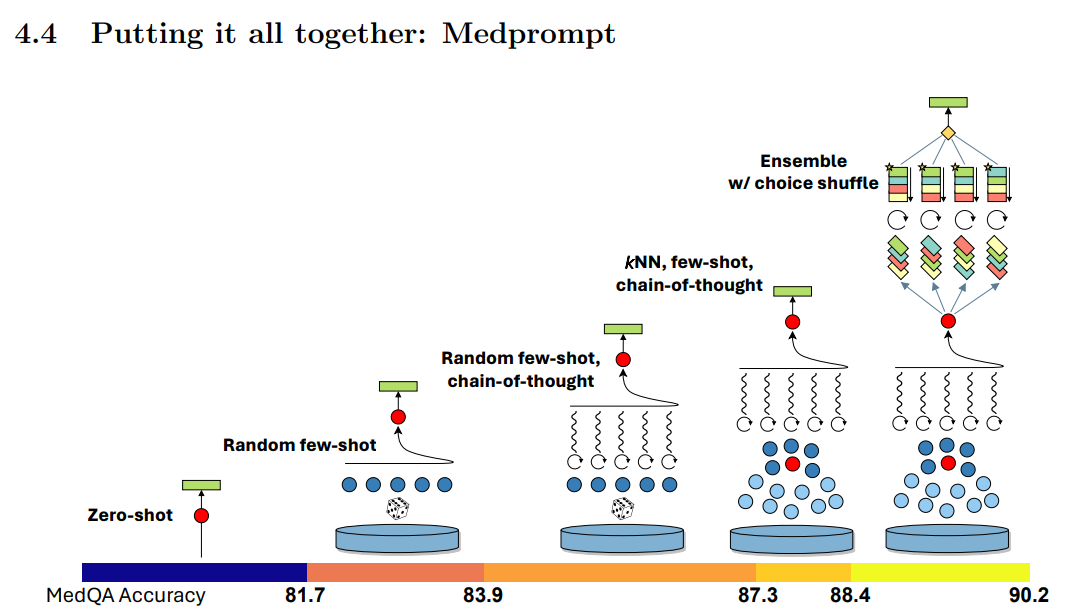
We can make a huge article about all of this but here is the premise of our claim:
Microsoft’s really clever team found a way to outperform Gemini Ultra which by the way is not out yet. Nobody can use it. Gemini Pro was released on December 12th of 2023.
GPT-4 has been in the market since Mar 14, 2023.
Microsoft’s team just proved the entire point of our mission here at PotenzaGPT.
The fear of missing out on new AIs, new versions and the like is unfounded if you do not even grasp how to properly use these LLMs.
Think about it, Microsoft just beat (not by a lot but still) a new technology that a rival company says it will perform a certain way and this 10 month old technology which is GPT-4 was able to beat them.
How? Prompting Engineering. Knowing how to properly use this technology.
Gemini Ultra used Chain-Of-Thought technique and after 32 prompts was able to reach that performance and with the MedPrompting and only after 31 prompts, they were able to beat this new supposedly great technology that nobody can even try.
Stop wasting your time on waiting for AGI or the next new version that will simplify how we interact with AIs.
Start mastering the skill of Prompt Engineering and get really ahead of the curve!
Thanks for reading!
Lastly, I will be making another article just on MedPrompt+ based on your feedback for this article. Stay tuned!




